So you wish to produce real quality medical device software? Testing is the time when you will show your true colors. Medical device imply that bugs can’t happen in production, because lives are at stake. As untested code never works, you have to invest a tremendous effort in hunting bugs using a variety of techniques.
Another reason why testing is of special importance for medical devices is that embedded systems are hard to update. I know of environments where it takes up to several years to manually update devices all around the world. Even if you have a good IoT solution to push updates, your clients might have a variety of good reasons to postpone them (such as their own internal, heavyweight validation process). Bugs will thus live for a long time in the wild. They shouldn’t escape. You might take more risks on a server that you can patch in a matter of hours for all your clients.
In addition, medical device regulations (IEC 62304 in particular) impose a test for every requirement and a traceability system to allow auditors to easily spot holes in the test system. But they let you a good degree of freedom about the testing techniques. Be smart in your choices.
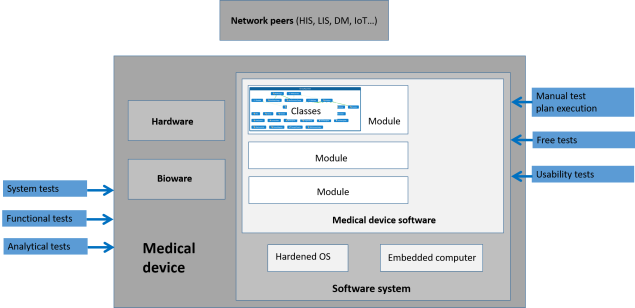
The following diagram classifies the kinds of tests I believe should be used to achieve the level of quality and safety required in the field. They grey areas represent the composition of components into a more and more complete medical device system. The green, purple and blue rectangles represent the categories of tests applied to sub-components. Check the color code below.
Broadly speaking, the wider the test, the costlier it will be to provide the required resources (from a virtual machine to a mini-lab or hospital setting full of medical devices) and the longer it will take to run them (from 1 ms to one day). For this reason, teams need to use each kind of test to its maximum extent to lower the need of more general tests, both for cost-effectiveness and good test coverage.
In this series of posts, my goal is to provide a return on experience and a general guidance on how to tackle these tests in the context of agile medical devices development. I’ve organized my thoughts in the same 3 categories that I’ve highlighted in the diagram, and that require different kinds of management.
Automated tests that run in the build system. One they’re written, apart from maintenance of broken test and build system performance, you need no effort to run them, so they run all the time.
Automated tests supervised by a tester. Require some planning, dedicated hardware and somebody to start them and to interpret the results, but they can be highly parallelized with other activities.
Manual tests. The costliest kind, requiring a human being during execution.
I deeply believe that automated tests alone cannot be sufficient for embedded systems. The key reason is that you need to test your software on its production hardware, which may include sensors and actuators. Your test runner virtual machines are not representative of this – at least because they have some integration with your CI. Continuous delivery is achievable for highly automatable and low-risk domain models –the consumer web for example. But in the project I run where we put the most effort on automated tests, with more than 3000 of them, manual testers are still able to find more than 150 bugs per iteration. Sure, test coverage could be better, one test should be added for every bug found. But getting too hardcore on this may create waste (some automated tests are just so difficult to write and maintain that it’s simply not worth it). Anyway, even if the automated test system was perfect, a human being would be required at some point. Users are real people, patients might be going through the toughest times of their lives; they should be assured that the medical device they rely upon has been manipulated by a fellow human being, and not by a dark army of cold virtual machines 🙂
Manual tests classification. Check out the overview for the bigger picture.
Before I dig into the specifics of manual testing with or without hardware and bioware, a few general considerations:
All kinds of manual tests incur dramatic costs to be run: I’ve seen projects with ten people full-time only for manual regression testing. And it’s a total waste: you could do it again thoroughly at the next commit! So these tests should be handled with care.
Their point is that a human being uses the software in the same conditions as the end user. Priceless. Testers will notice so many little details, maybe not directly linked to the test plan being executed, that would annoy end users! They will sport ergonomic inconsistency. They will establish far-fetched correlations between seemingly unrelated things. Testers are smarter than test procedures, they see what lies beneath.
The very fact that manual test are required implies a delivery process for manual testers (for purely manual test execution and supervision of semi-automated tests). That leads us to the two-phase iteration.
Manual tests running on software alone
Structured manual tests are the most classical way of testing that regulators expect: test plans written and validated before test execution, tests plans rigorously executed by human beings as if they were robots. My advice here is to be careful about productivity:
Set up an environment that automates trivia work surrounding manual test execution. A real-world counter-example is to print manual test procedures, complete them and sign them with a pen. A better way is follow this process digitally, including the storage of the results in such a way that it can be included in the traceability matrix. Doors is pretty good at this, but I’m sure there are other good tools out there. Just don’t do it manually, it’s pure waste.
Measure manual test procedure execution time and maintain a database that allows you to predict the time required to execute a certain strategy (which will guide you in finding a good balance between test coverage and test effort when defining the test strategy answering to an impact analysis).
Define indicators related to that execution time and look for strategies to minimize it.
One hint for this minimization: have developers help testers by writing scripts to set up environments fast, fill databases with ready-to-use data, replace hardware and networks peers with faster stubs. Testers can also help themselves by automating test prerequisites (preparing the system to reach a certain state before starting the real test) once they master UI test automation tools.
Manuel tests are an excellent way to test for weird system conditions.
Suppose your medical device can be used in sites with poor power supply, hence has to resist to unexpected blackouts. Check it out by savagely removing the power cord during load test, restarting, and ensure that the app knows how to spot interrupted stuff, notify it to the end user, clean the mess, restart what has to be restarted. Is that database really ACID? Aren’t there caches somewhere (in the OS or in the disk itself) that retain mandatory data that will get lost when pulling off the cord?
A similar condition is operating system failure. It’s possible to provoke on purpose a Windows Blue Screen Of Death with special drivers. Your data should resist it.
Suppose there are separate calculation units for real-time automation and for the GUI. What happens when you pull off the cable between both and plug it again a while later? Can your system recover gracefully?
What happens when a separate process on your OS goes wild and eats your CPU? Your app should not break – typically queue work items and diminish the processing pace, but not break. This can be simulated with tools (BurnCPU for example).
Suppose you have encrypted a few sensitive columns in the database with a unique key stored on the computer. The computer burns. Users have a backup of the database somewhere but they need the recovery key for the encrypted columns. Have you stored a backup key in a safe place? Are you really able to inject it on a new PC with a fresh app install with an old backup (typically with a few schema migrations) and have everything work fine? You don’t want your users to loose their data, do you?
Windows Blue Screen Of Death
Where manual testers really shine is when performing free testing. They explore the app in crazy ways. They provoke havoc on purpose. They find new issues by looking for undesired behavior outside the requirements. People tend to overlook this technique because it doesn’t exist regulation-wise (no test plan, no traceability matrix) and they already feel overwhelmed with regular formal testing. But if you’ve done a good job automating and working on productivity, if you use manual testing only where it’s effective, you can certainly save some time for free testing and progress towards the greater goal: finding bugs before they kill a patient. As an added bonus, they’re good for tester morale.
Manual tests running on hardware and bioware
I know three categories of tests that imply physical stuff (overlooking clinical trials, which serve a very different purpose and have their own constraints):
System testing is about integrating a whole system and testing how well the different parts fit together. It usually involves pushing individual parts outside of their normal operations limits. It may also involve testing the features required to service the system in the field, and generally everything that is done behind the scenes to make sure the device has top performance.
Functional testing is about testing the system completely as an end-user would.
Analytical testing is about performing large series of tests involving real biological material to assess to biological performance of the whole system.
These tests imply that the software is tested as part of a bigger system including hardware (a device) and biological components. This is mandatory to make sure that the system as a whole works. But from a software perspective, this has a number of drawbacks:
Hardware drawbacks:
Hardware takes time to develop and produce. Hardware is harder to change, so people struggle more to get it right the first time, and may get stuck into Analysis Paralysis. Feedback loops are awfully slow – maybe a couple of months, even quarters, if components are made by partners and new contracts need to be negotiated. Consequence: there may be no hardware when you need it. And when it finally arrives, guess what? The project is late, there is no time left for bug-hunting the software.
Hardware prototypes are expensive. I’ve seen such prototypes exceed the price of a brand-new car. So there may be a shortage of testing stations.
Hardware gets broken. This is especially true with prototypes – the hardware guys also have to spot their hardware bugs. While they fix them, the testing session is over.
Hardware is slow. Slow to initialize, slow to reach operating temperature, slow to change state. Nothing can be executed faster in real conditions. The tests will be slow.
Hardware is dangerous. Engineers can get electrocuted, have fingers cut or crushed. This is especially true with prototypes: safety is a result of design and may not be guaranteed while the design phase isn’t done. So extra care must be taken with hardware.
Biological stuff drawbacks
Biological material is also dangerous. Extra care need to be taken to clean everything and make sure no tester gets contaminated with some nasty germ. This slows tests down.
Biological material may be scarce. Either because it’s costly, or because it’s genuinely rare (e.g. sample coming from patients with certain uncommon pathologies). So the sheer number of test runs may be limited.
These practical drawbacks have a nasty impact on test productivity, compared to software tests where anything annoying can be mocked. For this reason, tests involving physical stuff should only be used to spot complex issues that cannot be revealed otherwise. For a system to work, every part has to work fine, and all of them must work well together. Spotting the cause of issues can be challenging. For example: does the bad quality control value we measure come from the way the sample has been defrosted or warmed up in the machine, has the heater a defect or has the electronic card gone wild, does the network tamper with the message or has the temperature threshold been truncated when stored in the database? These problems are difficult to solve. They take time. And they arise when the device starts working – this means close to the end of the project, when deadlines are close, budgets are depleted, and everyone is very anxious with getting that nightmarish piece of engineering finally released. You don’t want to add to the confusion by disclosing software problems that could have been spotted earlier, in isolation.
So my main advice about system testing from a software engineering perspective is that system testing is not a time to find software bugs. Use all the techniques discussed in the preceding sections to spot them earlier. If you do your job well, you should hear about very little bugs at these stages.
Load test. Load tests are typically a special kind of integration tests. The idea is to ensure that your app works with the expected performance criteria at maximum capacity by testing it in conditions an order of magnitude more demanding. Both performance and capacity criteria should be precisely defined in specifications and related to a real user need, otherwise the temptation to lower the bar will be great. These tests are difficult to make pass and as such deserve a user story of their own. But they are an excellent bug finder: you will encounter those rare conditions that otherwise would happen only at client sites. They are a must have. While I recommend running some load tests in the build (which allows you to break the build as soon as a toxic commit kills performance, or to easily monitor the duration of these tests over time), at some point you must run them on the target hardware and OS and guarantee that the performance objectives will be met in production conditions.
Stamina tests. This time, the device operates at normal capacity, but for a long time. For example, I work on a medical device that is meant to run with one shutdown per week: it has to be tested for one week of continuous work (or more). Other kinds of interesting and surprising bugs can be spotted here, such as tiny memory leaks or hidden timeouts – what happens if the app is left open without activity for more than twenty-four hours? A very interesting way of performing stamina testing is to capture real production activity and to repeat it – in which case it also serves as regression testing.
Automated tests written by testers. Automated testing tools such as Ranorex or TestComplete allow testers to set up tests that exercise the GUI as an end user would and check the display. As such they are pretty global integration tests. They can be run in the build or on the same computer as the medical device, to be even more global tests (which is why I’ve classified them here). The easiest way for testers to write them is to record manual test sessions. But on the long run we have found more productive to write large portions of them directly with code, which helps to reuse them across projects. We have also found that such automated GUI tests could be very handy to automate the setup of manual tests (putting the SUT in a certain state before starting the test). Let’s face it: the entry cost is real. You need to study the market and choose the right tool (vendor lock-in is very likely given the cost of your tests and their adherence to the specifics of the tool), to get acquainted with the tool, to create a team responsible for these automated UI tests, to set up good communication channels between this team and the dev teams to avoid breaking tests when controls are renamed or refactored, to tweak your UI to help the tool find controls, to put everything in the software factory, to link the tests to requirement numbers and get their results into the traceability matrix, to provision the maintenance costs of these tests. But the rewards are great: imagine you could run your whole manual test plan in one night on your servers, imagine you could transform wasteful test execution time into an investment (repeatable test procedures), imagine you could thus get enough time for your testers to perform free testing – wouldn’t that be a lot more productive and interesting? Wouldn’t you find more bugs?
TestComplete test editor
Test with network peers. Modern medical devices can no longer be off the grid: medical and laboratory staff need them to receive orders and send results through the healthcare organization network (with protocols such as HL7, ASTM, DICOM…), they may interact with non-embedded software that is easier to develop and maintain (Data Managers, for example), and they might interact with an IoT solution that helps keep them in optimal operating conditions and add remote services (such as allowing patients to inspect their medical records, or apply artificial intelligence technique to provide clinical decision support). All these wonderful features relying on networks need to be carefully tested. While low-level interactions (such as protocol handling or basic conversations between servers) should be tested in the build to provide fast feedback to developers and extensive edge case testing, at some point the integration must be tested in more realistic conditions: real hardened operating systems, real network cards, real cables or wifi, real firewalls and NATs, real DNSs, real intrusion detection systems, real production server hardware… I’ve classified network peers testing in the semi-automated category since you can typically script part of the test scenario, but will still need some degree of human intervention to set them up, start them and analyze the results (until the day the healthcare industry has fully moved to continuous delivery, but we still have a long way to go when embedded systems are involved).
Security testing. Network peers lead us to cybersecurity. As anything, security doesn’t work until it has been tested. There is much more to security than intrusion testing, but the latter at least guarantees that your security measures were able to repel one professional attacker. It’s doesn’t guarantee your device can’t be hacked, but it says it’s not that easy. To perform the attack properly, the auditor will need access to the device in real conditions (real computer, real hardened OS with real vulnerabilities). Trying to hack a system involves the expert manipulation of tools (such as MetaSploit) that automate attacks or entire catalogs of attacks and gather results to show vulnerabilities to the dev teams. I wouldn’t run such tools in a build system since they can easily compromise your IT infrastructure – they should be run only in a controlled, totally disconnected environment.
In my experience, writing and make pass the unit tests that act as guardians of a piece of code will take about twice the time required to write that piece of code alone. But that doubled time will include most of the debugging. As a developer, would you rather like to write unit tests or to debug? Would you rather fix things when they are fresh in your memory or two months later? Do you like to have your work really finished and move on to the next challenge, or be constantly caught up by your past and shameful mistakes? When somebody else breaks something in that functional area you’ve been working on some time ago, would you rather spend one day investigating their blunder to determine if it’s their responsibility to fix it, or instantly see in the CI what commit likely broke your unit test? Would you rather refactor constantly stuff you don’t like in your code or be paralyzed by the fear or breaking things in lesser-known areas of the code without any safety net? When you have to modify some code written by someone gone long ago, do you want to find it equipped with unit tests to help you get acquainted with the beast? I believe that automated tests are profitable, but on the long run. There is a quite high entry cost. Introducing automated tests late in a project is not quite so profitable. It must by a constant effort of everyone in the team with the goals of catching bugs, of inciting to decoupled design, of allowing design evolution by providing a safe environment for refactoring. But isn’t that exactly what we’re pursuing when developing medical devices? Good design, few bugs?
Anyway, the most economically interesting part with automated tests is that running them is cheap. Sure, some time will be required to take care of the production of all the servers and build agents, and to maintain the build scripts and build tools configuration in good shape. But this cannot be compared with the incredible cost of manual testing campains. Automated testing means putting effort in designing stuff, not repeating an effort which outcome is of very temporary value (until the next commit, or luckily the next version); it means climbing higher in the value chain. The very fact that it is so cheap allows the sheer number of tests run for every release to grow dramatically (compared to manual testing), which actually decreases the number of defects found in an end product – if you take advantage of the discipline.
Running tests almost for free is what makes automated testing so paramount to agile development. You can’t deliver often if you can’t test cheap and fast. And you can’t refactor if you have no safety net. A development that’s not iterative and evolutionary can’t be agile at all.
Going back to the schema of the introduction, here are the tests we will focus on in this section (green boxes).
Automated tests have the freedom to exercise small software components. To do so, they replace the environment of the System Under Test (SUT) with mocks and stubs, at any level. They are meant to run in virtual machines (or, someday, containers), which means they don’t run with the target embedded computer and they don’t run with the production OS (as they necessarily imply installing at least one testing dependency to run the tests and gather the results, and no dependency should be shipped in a production OS that is not required to operate the medical device, as this might increase risks regarding safety and cybersecurity). This freedom to mock collaborators of the SUT means it is possible to thoroughly test edge cases that are difficult or impossible to test by other means. This is especially important for programs that are meant to operate sensors and actuators and give life to an automaton, something that inherently has state: thanks to automated testing, you can easily test many configuration of the medical device, and simulate every possible error code of every possible sensor and actuator (at least at the level of the layers closest to the hardware, before combinatorics become overwhelming). You can also test what’s happing with a large variety of biological measurements or behaviors – even simulating phenomena that seldom happen in reality). Automated tests rock to achieve reliability.
Here are some guidelines on the use of the 3 main categories of tests that can easily be executed in the build:
Unit tests. Unit tests are written to exercise a class or a couple of classes. The idea here is to test your basic algorithms decoupled from their environment. They prove worth themselves when the algorithms are not trivial – unit-testing boilerplate code is not profitable, I’d rather leave that to module and integration testing. The point of unit tests is, since you work at so small a scale, you can test all execution path and conditions, even those that are not meant to happen in production – but that eventually will. For example, suppose your write an algorithm for counting cells in an image. You should test that algorithms with a nice quantity of images taken from production condition (say one hundred) with a carefully chosen variety of concentrations for the different cell types. And then error cases: inappropriate formats, corrupted images, pictures of the sea… Once these tests are written, you must be confident enough to say: results will be good and errors will be gracefully detected.
Module testing. I’ve found many definitions of a module on the web, but here’s the one I use in this blog: a module is a complete binary entity that can be started and shut down– typically an executable. Module testing hence means testing the module as it will be in production (compiled in Release mode, all relevant compiler optimizations on, signed…). You mock the collaborators of the module (typically making them have a known behavior) and test the latter through its production API. At that scale, you won’t test all execution paths, but ensure that most features of the module that will be delivered to production work.
Integration testing. In these tests, you exercise several modules but you still mock some of their collaborators (e.g. network peers, fake machine hardware). Here you can test for interesting things such as complete app startup and shutdown, global error handling (are errors detected, and a nice error report generated, hopefully sent to the dev team?), and maybe run them on the target production OS (along with all hardening and branding features). For example, one of my teams created integration tests where the C++ and Straton automaton code (complete except for the stubbed actuator and sensor level) was running inside a virtual machine with Linux-preemptRT OS and interacted with the business code running in a Windows 7 of the build agent (which was quite different from the hardened production OS). These tests, by running complete biological tests execution, complete startup and shutdown sequences, as well as key maintenance behaviors, guaranteed many things about the execution of the automation code in its target OS and its interaction with the upper layer.
Organizational factors to make automated testing possible
Working in a regulated industry, to fully take advantage of automated testing, you have to legalize it. To be suitable for use in the traceability system, all kinds of automated tests must be legitimated. This means that management plans and procedures need to introduce them properly, and that every tool in the chain must be documented, put in configuration control and formally validated. Tests have to reference requirement numbers in such a way that they appear in the tests results, which will feed the traceability matrix (for example, write the ids of the requirements covered by each test in NUnit’s Description attribute).
Give time for automated tests. Automated tests take time. If management doesn’t provide this time, they won’t happen by magic. A technique I find useful is to constantly repeat in planning poker sessions that automated tests are a mandatory part of the job, and that they should be part of the estimate. Difficult tests (such as automated load and stamina tests) must have a user story of their own, and with high estimates (these things are always a lot harder than they appear). As with all things related to long-running quality efforts, a constant care must be taken that will affect the sort-term velocity of the team. But everyone (up and down) has to get used to that velocity if it is required to write good, reliable, safe medical device software. One more reason to start it from the beginning: automated testing must be part of the natural rhythm of the team.
Time is the soil in which automated tests can grow. The ideal of quality is the seed. But what are the fertilizers you can use to make them flourish? Apart from technical factors that we’ll delve in soon, what is required is an automated testing culture.
Writing good automated tests must be pervasive in the development culture. Every developer should expect to create them and fix them when they’re broken. In fact, should developers be deprived from this constraint, they should find it unacceptable and fight hard to have automated tests introduced. In addition to this distributed responsibility, a dedicated team is useful to take care of the more difficult work regarding test: maintaining and polishing base test classes and shared stubs, updating libraries and introducing new ones when appropriate, spotting and annihilating sources of randomness in tests results, improving test performance, deleting obsolete or not-that-profitable old tests. Having tests that pass fast, deterministically and successfully (tests that are never left broken for long) makes a long way towards creating and expanding that automated testing culture.
Good KPI visible everywhere (including sprint reviews) can help. I’ve used the raw number of tests (motivating since always increasing, but not very meaningful), the number of tests created by iteration (a good indicator of the persistence of the practice in your team), the test coverage, the status of a few key and difficult tests.
Management should constantly show its care. By ranting about broken or random tests. By praising accomplishments (such as lowering the number of broken tests, fixing randomness, achieving victory with difficult load or stamina tests). By watching the state of the build. By investing the energy in building the culture and overcoming the necessary obstacles. By allocating time and resources to the endeavor.
Here are my favorite psychological tools to deal with broken tests.
Box. I built a box with funny pictures to be put on the desk of every developed convinced to have broken the build so that they feel peer pressure to fix things fast. But be careful with this one, it has to be fun and light – otherwise it might create a weird atmosphere in the open space or even turn to moral harassment.
Build guardian. When there are many tests, many developers, no gated commit and when feedback time is long, someone is required to watch for the build: the build guardian. His or her job is to analyze failed tests and assign investigations (either by determining the likely culprit by looking at the commits since the last time the test passed, or by assigning them randomly). This person must have enough authority that his or her decisions are respected.
Instant feedback. Having a nice continuous integration tool with appropriate alerts (by mail, system tray, Slack…) when things need attention will help maintain quality in tests. I’ve appreciated using TeamCity the last few years. We also put a LED indicator in the open space to shout for broken tests (and stand-up meeting time J). If you happen to have a certain percentage of broken tests on a regular basis, the XFD can also be used to display the number of tests passing and failing. Or display silly jokes.
Technical factors to make automated testing possible
A necessary condition for automated tests to exist is to have an architecture that makes writing them easy enough – let’s call it test-friendly architecture. This means a highly decoupled architecture: massive use of dependency injection is a key technique, mocks and stubs are required, onion architecture can also help. The interesting thing here is the reverse effect: once you seriously start your automated testing journey (hopefully at the beginning of the project), you find yourself adding interfaces to write test doubles (to mock the hardware, a remote server, the database…), injecting dependencies, using in isolation just a few classes (to keep the test lights and fast)… and the architecture gets better. Testing the software is much more demanding to the design that all these extension points you consider for the future. As Bob Martin coined it, “The act of writing a unit test is more of an act of design than of verification”.
You need a good continuous integration tool to run the builds. You need enough build agents to handle the load, ideally a cloud with dynamic provisioning. Build agents should be identical, hopefully frequently restored to a reference state to avoid drifting apart. But sometimes differences in configuration between build agents will be necessary to minimize license costs (for example, install expensive tool X used only for C++ static checking on agent A).
TeamCity build agents configuration
The configuration of the build system (build scripts, build config…) should be kept in source control. Have a policy on this repository so that it is easy to restore the version of the build system to a former release branch.
If you want developers to pay attention to broken tests and fix them, they should never break for no reason. A couple of hints to achieve better test predictability :
No dependency with time. Since the performance of virtual machine build agents and developers’ machines are likely different, timing will vary in both environments. It’s very frustrating to fix a bug that breaks only in the CI but works on all dev machines. The cure here is to use events to synchronize the parts of your code that need synchronization, but never time (no sleeps). If you really need time, encapsulate it (through some kind of ITimeProvider) so that you can fake it deterministically in your tests (to return always the same known value, for example).
Test isolation. Tests MUST be independent from one another. This probably means that the database will have to be re-generated or restored for every module of integration tests. This will take time. But tests failures provoked by other tests are a worse evil.
Test predictability. Sometimes an unpredictable behavior enters the code – several consecutive executions of the tests for the same revision of the code don’t yield the same results: test X once passes, once fails. Those unbearable sources of randomness must be mercilessly hunted and annihilated: they will very fast kill the faith of developers in tests – hence the intensity of their effort in maintaining them.
Sometimes it’s not easy to spot these sources of randomness, especially if they don’t happen on developer machines. But there’s one thing you can do: put these tests in quarantine – a special build for ill-mannered tests marked by an infamous attribute, a kind of jail where they can be reeducated before they are reintegrated in proper society again. This way, they won’t harm the production of well-behaving tests. And fixing them will be easier if they can be run in isolation, repeatedly, in the build agent environment.
Crucial tests. You can identity a couple of crucial tests without which you know your app is broken (such as starting and executing the most typical feature of the app). These tests should be executed with the build and break it when they fail (assuming you have so many automated tests otherwise that they have been distributed over several build projects).
The best of all tools to protect tests is the gated commit. Developers submit their branches to the CI, which passes the required build scripts (including static checks and tests). If the build is good, the branch is merged. If not, the developer is notified but nobody else is disturbed (which in itself tames the natural mayhem of large teams with many commits and helps build a more relaxed and focused environment). The amount of tests to put in your gated commit criteria should be as high as your pool of build agents allows you to process in a short enough time – I think 12 hours would be my maximum here, ten minutes would be ideal but difficult to achieve with many tests. If you can put them all and your tests are truly deterministic, the build of the main branch will always be green! But be careful: sources of randomness in tests might block your entire delivery pipeline, make sure they are taken care of.
Gated commit example. Dev 1 and dev 2 create branches from master. Dev 1 tries makes a pull request, which is rejected because the build script detected a problem (for example, a broken architecture rule). Pull request 1’ fixes this. Pull request 1’ is successfully merged into the integration branch, where the build script runs fine: pull request 1’ makes it to the master branch, where everybody can see it. Things are different for dev 2: the build script passes successfully on the branch alone, but fails on the integration branch (for example, a broken test) because of the commits of pull request 1’, which create a nasty side effect (pull requests 1’ and 2 run fine separately, but not together) that dev 2 had no way of knowing, because pull request 1’ had not yet made it to the master branch when dev 2 performed the last rebase onto master. No problem, that’s what the integration branch is for. Pull request 2’ fixes the broken test, and makes it to the master branch.
To set up a gated commit, you need a DVCS enough at merging that most automatic merges succeed most of the time (git is pretty good at this) and support from your CI (we used TeamCity and GitHub together to achieve gated commit with limited effort).