This article is part of a series of posts about medical devices software testing:
- Overview
- Automated tests that run in the build system.
- Automated tests supervised by a tester.
- Manual tests.
I deeply believe that automated tests alone cannot be sufficient for embedded systems. The key reason is that you need to test your software on its production hardware, which may include sensors and actuators. Your test runner virtual machines are not representative of this – at least because they have some integration with your CI. Continuous delivery is achievable for highly automatable and low-risk domain models –the consumer web for example. But in the project I run where we put the most effort on automated tests, with more than 3000 of them, manual testers are still able to find more than 150 bugs per iteration. Sure, test coverage could be better, one test should be added for every bug found. But getting too hardcore on this may create waste (some automated tests are just so difficult to write and maintain that it’s simply not worth it). Anyway, even if the automated test system was perfect, a human being would be required at some point. Users are real people, patients might be going through the toughest times of their lives; they should be assured that the medical device they rely upon has been manipulated by a fellow human being, and not by a dark army of cold virtual machines 🙂
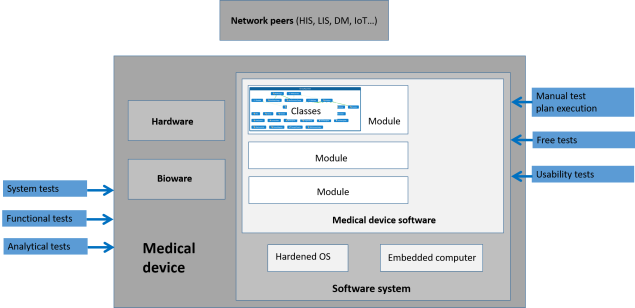
Manual tests classification. Check out the overview for the bigger picture.
Before I dig into the specifics of manual testing with or without hardware and bioware, a few general considerations:
- All kinds of manual tests incur dramatic costs to be run: I’ve seen projects with ten people full-time only for manual regression testing. And it’s a total waste: you could do it again thoroughly at the next commit! So these tests should be handled with care.
- Their point is that a human being uses the software in the same conditions as the end user. Priceless. Testers will notice so many little details, maybe not directly linked to the test plan being executed, that would annoy end users! They will sport ergonomic inconsistency. They will establish far-fetched correlations between seemingly unrelated things. Testers are smarter than test procedures, they see what lies beneath.
The very fact that manual test are required implies a delivery process for manual testers (for purely manual test execution and supervision of semi-automated tests). That leads us to the two-phase iteration.
Manual tests running on software alone
Structured manual tests are the most classical way of testing that regulators expect: test plans written and validated before test execution, tests plans rigorously executed by human beings as if they were robots. My advice here is to be careful about productivity:
- Set up an environment that automates trivia work surrounding manual test execution. A real-world counter-example is to print manual test procedures, complete them and sign them with a pen. A better way is follow this process digitally, including the storage of the results in such a way that it can be included in the traceability matrix. Doors is pretty good at this, but I’m sure there are other good tools out there. Just don’t do it manually, it’s pure waste.
- Measure manual test procedure execution time and maintain a database that allows you to predict the time required to execute a certain strategy (which will guide you in finding a good balance between test coverage and test effort when defining the test strategy answering to an impact analysis).
- Define indicators related to that execution time and look for strategies to minimize it.
- One hint for this minimization: have developers help testers by writing scripts to set up environments fast, fill databases with ready-to-use data, replace hardware and networks peers with faster stubs. Testers can also help themselves by automating test prerequisites (preparing the system to reach a certain state before starting the real test) once they master UI test automation tools.
Manuel tests are an excellent way to test for weird system conditions.
- Suppose your medical device can be used in sites with poor power supply, hence has to resist to unexpected blackouts. Check it out by savagely removing the power cord during load test, restarting, and ensure that the app knows how to spot interrupted stuff, notify it to the end user, clean the mess, restart what has to be restarted. Is that database really ACID? Aren’t there caches somewhere (in the OS or in the disk itself) that retain mandatory data that will get lost when pulling off the cord?
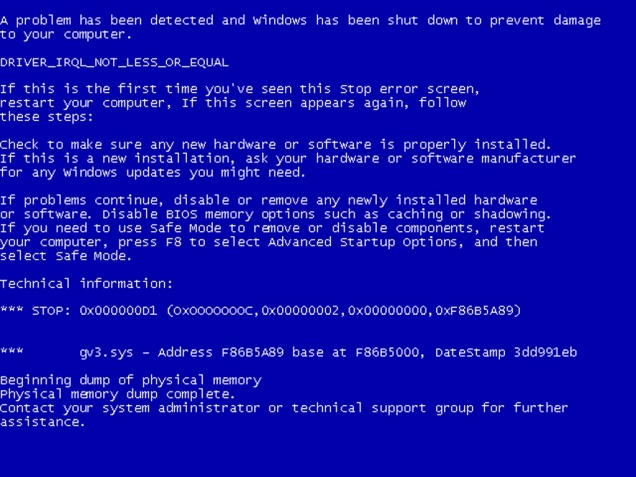
- A similar condition is operating system failure. It’s possible to provoke on purpose a Windows Blue Screen Of Death with special drivers. Your data should resist it.
- Suppose there are separate calculation units for real-time automation and for the GUI. What happens when you pull off the cable between both and plug it again a while later? Can your system recover gracefully?
- What happens when a separate process on your OS goes wild and eats your CPU? Your app should not break – typically queue work items and diminish the processing pace, but not break. This can be simulated with tools (BurnCPU for example).
- Suppose you have encrypted a few sensitive columns in the database with a unique key stored on the computer. The computer burns. Users have a backup of the database somewhere but they need the recovery key for the encrypted columns. Have you stored a backup key in a safe place? Are you really able to inject it on a new PC with a fresh app install with an old backup (typically with a few schema migrations) and have everything work fine? You don’t want your users to loose their data, do you?
Where manual testers really shine is when performing free testing. They explore the app in crazy ways. They provoke havoc on purpose. They find new issues by looking for undesired behavior outside the requirements. People tend to overlook this technique because it doesn’t exist regulation-wise (no test plan, no traceability matrix) and they already feel overwhelmed with regular formal testing. But if you’ve done a good job automating and working on productivity, if you use manual testing only where it’s effective, you can certainly save some time for free testing and progress towards the greater goal: finding bugs before they kill a patient. As an added bonus, they’re good for tester morale.
Manual tests running on hardware and bioware
I know three categories of tests that imply physical stuff (overlooking clinical trials, which serve a very different purpose and have their own constraints):
- System testing is about integrating a whole system and testing how well the different parts fit together. It usually involves pushing individual parts outside of their normal operations limits. It may also involve testing the features required to service the system in the field, and generally everything that is done behind the scenes to make sure the device has top performance.
- Functional testing is about testing the system completely as an end-user would.
- Analytical testing is about performing large series of tests involving real biological material to assess to biological performance of the whole system.
These tests imply that the software is tested as part of a bigger system including hardware (a device) and biological components. This is mandatory to make sure that the system as a whole works. But from a software perspective, this has a number of drawbacks:
- Hardware drawbacks:
- Hardware takes time to develop and produce. Hardware is harder to change, so people struggle more to get it right the first time, and may get stuck into Analysis Paralysis. Feedback loops are awfully slow – maybe a couple of months, even quarters, if components are made by partners and new contracts need to be negotiated. Consequence: there may be no hardware when you need it. And when it finally arrives, guess what? The project is late, there is no time left for bug-hunting the software.
- Hardware prototypes are expensive. I’ve seen such prototypes exceed the price of a brand-new car. So there may be a shortage of testing stations.
- Hardware gets broken. This is especially true with prototypes – the hardware guys also have to spot their hardware bugs. While they fix them, the testing session is over.
- Hardware is slow. Slow to initialize, slow to reach operating temperature, slow to change state. Nothing can be executed faster in real conditions. The tests will be slow.
- Hardware is dangerous. Engineers can get electrocuted, have fingers cut or crushed. This is especially true with prototypes: safety is a result of design and may not be guaranteed while the design phase isn’t done. So extra care must be taken with hardware.
- Biological stuff drawbacks
- Biological material is also dangerous. Extra care need to be taken to clean everything and make sure no tester gets contaminated with some nasty germ. This slows tests down.
- Biological material may be scarce. Either because it’s costly, or because it’s genuinely rare (e.g. sample coming from patients with certain uncommon pathologies). So the sheer number of test runs may be limited.

These practical drawbacks have a nasty impact on test productivity, compared to software tests where anything annoying can be mocked. For this reason, tests involving physical stuff should only be used to spot complex issues that cannot be revealed otherwise. For a system to work, every part has to work fine, and all of them must work well together. Spotting the cause of issues can be challenging. For example: does the bad quality control value we measure come from the way the sample has been defrosted or warmed up in the machine, has the heater a defect or has the electronic card gone wild, does the network tamper with the message or has the temperature threshold been truncated when stored in the database? These problems are difficult to solve. They take time. And they arise when the device starts working – this means close to the end of the project, when deadlines are close, budgets are depleted, and everyone is very anxious with getting that nightmarish piece of engineering finally released. You don’t want to add to the confusion by disclosing software problems that could have been spotted earlier, in isolation.
So my main advice about system testing from a software engineering perspective is that system testing is not a time to find software bugs. Use all the techniques discussed in the preceding sections to spot them earlier. If you do your job well, you should hear about very little bugs at these stages.

3 thoughts on “Medical devices software testing: manual tests”